
I've always had Western Digital drives, but recently I picked up a Seagate 500GB 7200.12 drive for cheap. I also have another 80GB Seagate EE25 in my car.
With Western Digital, the SMART seems to be intuitive and if the read error rate is non zero, then it could indicate you are having a problem. With Seagate however, the read error and hardware ECC recovered values are always high and always increasing. But from my understanding this is normal. Im guessing it is normal for a drive to have read errors all the time, but as long as it is corrected by ECC then you are fine (WD probably covers this info up?).
What SMART values do you guys usually pay attention to that may indicate a drive is failing? Just the current pending sector and reallocated sector values? Strangely, I had a WD drive that had a current pending sector of 50+, but after I wrote zeros to the drive and formatted, that value went back to 0...so I am unsure how to interpret this.
How do you interpret Seagate's SMART data? Signs of failure?
Moderators: NeilBlanchard, Ralf Hutter, sthayashi, Lawrence Lee
This is good info for all drives.
Reallocated_Sector_Count
Anything other than 0 is bad, but how bad depends on when the drive got them, and how long ago, if the last bad sector was reallocated 2 years ago you are probably OK now, as the problem has appeared, been fixed and has not come back. If you get a bad sector, you will likely get more, and the vauge statistic is that a drive that starts to get bad sectors will be trash within 6-months.
Reallocated_Event_Count
This can be a little confusing, you may get an "event", but the sector is never actually reallocated, this is usually due to a problem reading/writing a sector, which has then been flaged as bad, but when the drive got around to reading/writing to it at a later date it was OK, and therefore not actually reallocated. This means that you can get a "Reallocated_Event_Count" that is higher than the "Reallocated_Sector_Count", this can usually be ignored unless you have some of the above and some of the following.
Current_Pending_Sector
This is simple, sector(s) are awaiting a further look to see if there really is a problem (there usually is). I often see these when windows is broken, and the drive already has a few Reallocated Sectors. If so, the drive is usually on its way out, remember the 6-month rule.
Offline_Uncorrectable
The drive is very likely in a bad way, but the only way to tell is to write data to the whole drive and see what happens.
UDMA_CRC_Count
This can be a serious issue and is usually due to cabling faults, there is no damage to the drive usually swapping out the data cable fixes this problem. If you have swapped the data cable there are only a couple of other options, your motherboard or HDD are causing "soft faults" that could be an indication of worse things to come. If you have a laptop, there is rarely a cable or adaptor that can cause any kind of data transmission faults so it wcould be an issue with the drive or the laptop.
Most of the rest are not very serious, and the above are the only ones I ever look at (which I do with every single drive, whether the HDD is a suspect or not, the amount of times I have looked at a machine that obviously has viruses etc AND bad sectors, at which point the viruses are usually not a problem as the drive probably needs to be replaced.
Andy
Reallocated_Sector_Count
Anything other than 0 is bad, but how bad depends on when the drive got them, and how long ago, if the last bad sector was reallocated 2 years ago you are probably OK now, as the problem has appeared, been fixed and has not come back. If you get a bad sector, you will likely get more, and the vauge statistic is that a drive that starts to get bad sectors will be trash within 6-months.
Reallocated_Event_Count
This can be a little confusing, you may get an "event", but the sector is never actually reallocated, this is usually due to a problem reading/writing a sector, which has then been flaged as bad, but when the drive got around to reading/writing to it at a later date it was OK, and therefore not actually reallocated. This means that you can get a "Reallocated_Event_Count" that is higher than the "Reallocated_Sector_Count", this can usually be ignored unless you have some of the above and some of the following.
Current_Pending_Sector
This is simple, sector(s) are awaiting a further look to see if there really is a problem (there usually is). I often see these when windows is broken, and the drive already has a few Reallocated Sectors. If so, the drive is usually on its way out, remember the 6-month rule.
Offline_Uncorrectable
The drive is very likely in a bad way, but the only way to tell is to write data to the whole drive and see what happens.
UDMA_CRC_Count
This can be a serious issue and is usually due to cabling faults, there is no damage to the drive usually swapping out the data cable fixes this problem. If you have swapped the data cable there are only a couple of other options, your motherboard or HDD are causing "soft faults" that could be an indication of worse things to come. If you have a laptop, there is rarely a cable or adaptor that can cause any kind of data transmission faults so it wcould be an issue with the drive or the laptop.
Most of the rest are not very serious, and the above are the only ones I ever look at (which I do with every single drive, whether the HDD is a suspect or not, the amount of times I have looked at a machine that obviously has viruses etc AND bad sectors, at which point the viruses are usually not a problem as the drive probably needs to be replaced.
Andy
Re: How do you interpret Seagate's SMART data? Signs of fail
Yes these errors occur on other drives also. They just don't report them the same way. For my old 80GB Seagate HDD the results are:speedboxx wrote: With Western Digital, the SMART seems to be intuitive and if the read error rate is non zero, then it could indicate you are having a problem. With Seagate however, the read error and hardware ECC recovered values are always high and always increasing. But from my understanding this is normal. Im guessing it is normal for a drive to have read errors all the time, but as long as it is corrected by ECC then you are fine (WD probably covers this info up?).
Code: Select all
Raw Read Error Rate 61 112478456 Good
Spin Up Time 99 0 Very good
Start/Stop Count 100 24 Very good
Reallocated Sector Count 100 0 Very good
Seek Error Rate 85 378843895 Very good
Power On Hours Count 87 11922 Watch
Warning: Power On Hours Count is below the average limits (88-100).
Spin Retry Count 100 0 Very good
Power Cycle Count 97 3238 Watch
Warning: Power Cycle Count is below the average limits (98-100).
Hardware ECC Recovered 61 112478456 Good
Current Pending Sector 100 0 Very good
Offline Uncorrectable Sector Count 100 0 Very good
Ultra DMA CRC Error Rate 200 0 Very good
Write Error Rate 100 0 Very good
TA Increase Count 100 0 Very good This is actually quite an interesting field, because the various manufacturers implement SMART in different ways.
I'll give some examples from my own seagate LP drive, one that is slowly failing (reallocated sectors increasing...), but still shows as OK in smart.
The interesting parts pertaining drive failure from this smart data sample is field 5, Reallocated_Sector_Ct, the raw value is at 58, but 0-255 value is still at 99 - with the "optimal" being 100, this means the firmware doesnt deem this to be very serious - yet, the treshold value is 36. At that point it will scream about drive failure, and rightly so. Just a few days ago reallocated sectors was 52, so its definently deteriorating.
Also you can see from the graph that several values fluctuate over time, unlike for example samsung drives, especially you can see Hardware_ECC_Recovered, Seek_Error_Rate and Raw_Read_Error_Rate going up and down depending on drive load.
Oddly enough raw_read_error_rate usually stays above 100, with "treshold" value being 006, apparently its operating "above optimal"(?)...
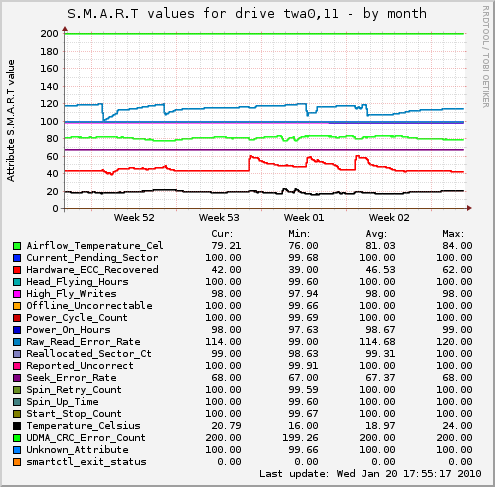
I'll give some examples from my own seagate LP drive, one that is slowly failing (reallocated sectors increasing...), but still shows as OK in smart.
The interesting parts pertaining drive failure from this smart data sample is field 5, Reallocated_Sector_Ct, the raw value is at 58, but 0-255 value is still at 99 - with the "optimal" being 100, this means the firmware doesnt deem this to be very serious - yet, the treshold value is 36. At that point it will scream about drive failure, and rightly so. Just a few days ago reallocated sectors was 52, so its definently deteriorating.
Also you can see from the graph that several values fluctuate over time, unlike for example samsung drives, especially you can see Hardware_ECC_Recovered, Seek_Error_Rate and Raw_Read_Error_Rate going up and down depending on drive load.
Oddly enough raw_read_error_rate usually stays above 100, with "treshold" value being 006, apparently its operating "above optimal"(?)...
Code: Select all
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 114 099 006 Pre-fail Always - 75441011 <--
3 Spin_Up_Time 0x0003 100 100 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 12
5 Reallocated_Sector_Ct 0x0033 099 099 036 Pre-fail Always - 58 <--
7 Seek_Error_Rate 0x000f 068 060 030 Pre-fail Always - 6502443 <--
9 Power_On_Hours 0x0032 098 098 000 Old_age Always - 2019
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 12
183 Unknown_Attribute 0x0032 100 100 000 Old_age Always - 0
184 Unknown_Attribute 0x0032 100 100 099 Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
188 Unknown_Attribute 0x0032 100 100 000 Old_age Always - 0
189 High_Fly_Writes 0x003a 098 098 000 Old_age Always - 2
190 Airflow_Temperature_Cel 0x0022 079 074 045 Old_age Always - 21 (Lifetime Min/Max 17/21)
194 Temperature_Celsius 0x0022 021 040 000 Old_age Always - 21 (0 16 0 0)
195 Hardware_ECC_Recovered 0x001a 042 039 000 Old_age Always - 75441011 <--
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 117763708291019
241 Unknown_Attribute 0x0000 100 253 000 Old_age Offline - 2415043908
242 Unknown_Attribute 0x0000 100 253 000 Old_age Offline - 741141060
Crap...after the 7200.11 fiasco, I was hoping Seagate would have improved their 7200.12 line. One thing that's good about the 7200.12 compared to the similar WD Blue is that there are less platters on the 7200.12...which I would have thought increases reliability. However, the Seagate doesnt have the touchless head load/unload like most modern drives since it's still a contact start/stop.